又换了个人看
玉涵大大
inc
等于“++”
1 | inc ax |
loop
循环
先看例子:计算212
1 | cs:codee |
cx(计数寄存器)存放为循环次数,s为标识指令地址(即从哪里开始循环)
先向cx存次数,标号:执行循环语句,最后loop+标记
本质上是指令指针(IP)的移动,先(cx)减一,再判断其值若不为0则转至s标号处,为0则执行下一条
汇编中 ffffh 编译器认为是标识符,要写为 0ffffh
将ffff;0~ffff:b单元的数据的和,结果储存在dx中
先将8位数据赋值到另一个16位寄存器bx中,再作加:
1 | cs:code |
段的应用
下两例:不将数据段栈段和代码段分开
技术算以下8个数据的和,结果放在ax中
1 | cs:code |
栈段
倒置数据
1 | cs:code |
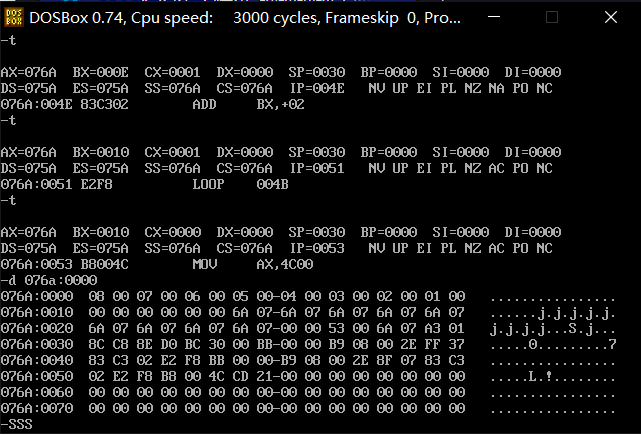
这两段代码认真debug看一下每一步
当然一般是分开的:
1 | cs:codesg,ds:datasg,ss:stacksg |
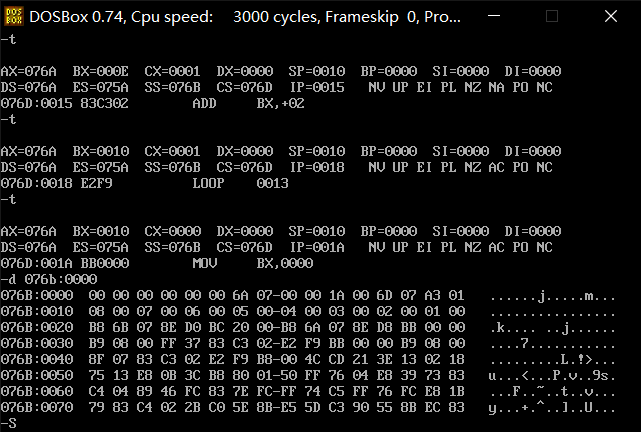
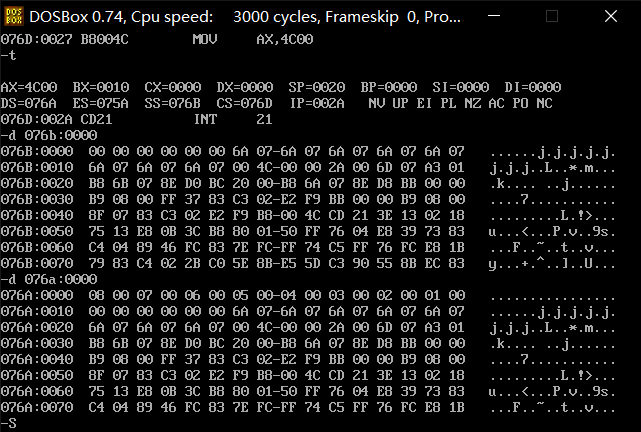
其它一些
debug中数据查看是每位反向的
debug默认输入16进制,编译时默认10进制
- and
常用对指定位置01
and al,10111111b
- or
常用对指定位置11
or al,10111111b
- xor(异或)
常用对寄存器置零1
xor ax,ax
- inc自增
- dec自减
- 小写字符=大写字符+20h
伪指令
- dw定义字类型变量,一个字数据占2个字节(16位)单元,读完一个,偏移量加2
- db定义字节类型变量,一个字节数据占1个字节(8位)单元,读完一个,偏移量加1
- dd定义双字类型变量,一个双字数据占4个字节(32位)单元,读完一个,偏移量加4
伪指令db、dw、dd都可以定义字符串,但最多的是用db来定义字符串,第一个原因是dw、dd定义的字符串到了内存中排序是相反的。 - dup是一个操作符,在汇编语言中同db、dw、dd等一样,也是由编译器识别处理的符号。它是和db、dw、dd等数据定义伪指令配合使用的,用来进行数据的重复。
dup的使用格式如下:
db 重复的次数 dup (重复的字节型数据)。
dw 重复的次数 dup (重复的字型数据)。
dd 重复的次数 dup (重复的双字数据)。
dup是一个十分有用的操作符,比如我们要定义一个容量为200个字节的栈段,如果不用dup,则需要大量的代码来进行定义。如果用dup的话:1
2
3stack
db 200 dup (0)
stack ends