哈希简谈(sha_256)
就是对任意长度字符数据都会生成唯一的长度为256bit长的哈希值,且不可逆的一种加密方式哈希函数,又称散列算法,是一种从任何一种数据中创建小的数字“指纹”的方法。散列函数把消息或数据压缩成摘要,使得数据量变小,将数据的格式固定下来。该函数将数据打乱混合,重新创建一个叫做散列值(或哈希值)的指纹。散列值通常用一个短的随机字母和数字组成的字符串来代表。
概要
主要参照:简易区块链C语言实现
博主讲得很清楚,简洁易懂,适合初学区块链
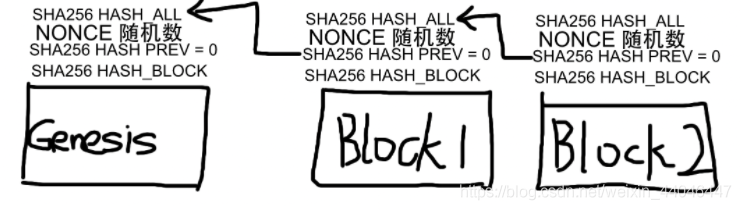
区块链数据结构
具体实现
1 | typedef union{ |
总之HEAD是核心,nonce的意义就在满足前导0要求,而前导0(不一定要求为0)的位数某种程度上控制了哈希运算的加密难度(复杂度)(比特币要靠挖就是算这个费算力),正因为有此不定的数据存在,使得哈希运算次数不定,则即使哈希加密可逆也无法解密出整个区块链保存的数据。又由于sha_all关联于sha_prev与sha_block,则任意修改区块链中的body数据,会使得sha_block不同,进而sha_all不同,直接影响了sha_prev无法衔接,可轻易识别非法修改数据。
这里前导0只要求两位(不然算的慢):
1 | int check_sha(BYTE text[32]){ // 检验是否为前导0 |
初始化程序
基本上掌握初始化原理就差不多弄得懂了
1 | void init(){ |
考虑加入时间戳是否就是在最后通过前导检测后,写入时多写一个时间关联数据,意义类似nonce随机数?
再分析一个函数
找最后一个块的函数:
1 | block find_last_block(){ |
自然可以简单修改为找对应需要数据区块的函数:
1 | block find_block(char* content){ // 读各个区块 |
可能复杂了,但是改的简单)