谈谈我的理解:关于数据存储,一般数据不都是在每个分机生成的区块中的,可以有单独数据库而区块链起到传输修改信息的作用(账本记录的就是入账出账信息,通过这些信息自然可得余额信息);争对我们的课题网上的架构不一定适用,我觉得可以在每个患者挂号时,为每一个患者创立独立的创世区块且记入数据库,然后根据需要,在构想的手环分机中,开始生成子需要传输信息的区块,且分机每次在成功传输信息后,仅需储存上一个区块值;可以简单的把区块生成视作加密,那么区块链就仅起到加密信息传输的作用(这样已经可以保证无法通过分机得到患者信息);所以我们还可以利用区块链分块储存的架构,将总数据库进行较大型的分布式储存。
以下文字为摘录
区块链 ≠ 分布式存储这篇强推
直观的角度来看,完整的区块链系统内部一定会包含一个「存储模块」,整体而言,区块链系统确实可以起到持久化数据的作用。
但是如果从这个角度出发,直接将区块链系统看作是一个数据库,这样的观点也是有待商榷的。
当我们站在区块链系统内部“数据存储”功能的角度看待“区块链系统”时,我们会发现,区块链系统具有确定性的系统架构、确定性的内部业务逻辑,以及一些通用的数据组织格式(比如:区块是一种append-only形式的数据、只有虚拟机执行指令的过程中会修改状态数据等)。区块链系统中的数据存储只需要满足这一套运转逻辑过程中的持久化需求即可,也就是说,区块链系统为其存储模块划定了比通用数据库更小的模块功能边界。
HASH
Hash是一个把任意长度的数据映射成固定长度数据的函数。例如,对于数据完整性校验,最简单的方法是对整个数据做Hash运算得到固定长度的Hash值,然后把得到的Hash值公布在网上,这样用户下载到数据之后,对数据再次进行Hash运算,比较运算结果和网上公布的Hash值进行比较,如果两个Hash值相等,说明下载的数据没有损坏。可以这样做是因为输入数据的稍微改变就会引起Hash运算结果的面目全非,而且根据Hash值反推原始输入数据的特征是困难的。
非对称加密
非对称加密技术在区块链的应用场景:
- 信息加密场景:主要是由信息发送者(记为A)使用接受者(记为B)的公钥对信息加密后再发送给B,B利用自己的私钥对信息解密。比特币交易的加密即属于此场景。
- 数字签名场景:由发送者A采用自己的私钥加密信息后发送给B,B使用A的公钥对信息解密、从而可确保信息是由A发送的。
数字签名,可以保证收到的文件没有被篡改,也可以保证发送者的身份。因为私钥生产了数字签名,私钥是不公开的。 - 登录认证场景:是由客户端使用私钥加密登录信息后发送给服务器,后者接收后采用该客户端的公钥解密并认证登录信息.
上述三种场景加密的不同之处主要在于:
- 信息加密是公钥加密,私钥解密,确保信息的安全性;
- 数字签名是私钥加密公钥解密,确保数字签名的归属性;
- 登录认证私钥加密,公钥解密。
如何存储大型数据
现在众多项目自称是基于区块链的,因为区块的数据大小,格式受限,其实是一些重要的信息,如账户信息,交易信息等放在区块里,其他的程序还是需要中心化的服务器执行,还有一些自身的需要存储的大数据,只是把其中的根节点HASH值,存入区块链。
大部分的的项目基于区块链是如下的一个思路,将需要用到区块链的部分抽离出来,逻辑上分成应用系统和区块链系统,用公链(如以太坊)实现区块链的功能,优点如下:
- 应用系统,区块链系统分类,最大程度的用原有中心化服务器系统。
- 利用公有区块链的网络安全强大,不可篡改等特性保证区块链功能。
基于以太坊的应用场景解决方案,一些大量数据可以做如下操作: - 在以太坊智能合约中维护自身区块链的头部信息; →网络安全、防篡改
- 自身区块链区块内容放在二级存储(安全的企业存储环境中);→自身信息隐私保护,省钱
- 对于历史头信息进行剪裁;→省钱
- 关联以太坊地址和自身身份;→不可抵赖
IAM的架构模式
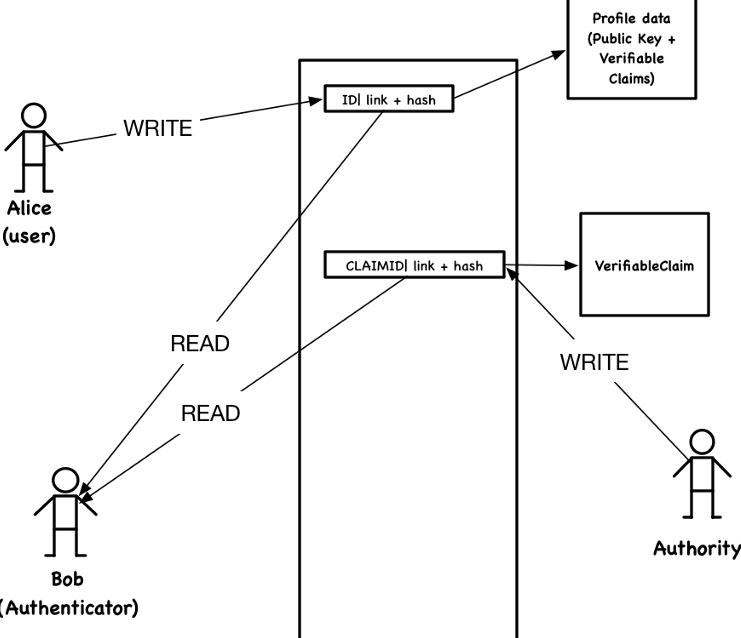
IAM环境中包括很多用户和服务提供商。IAM系统为每个用户分配 一个账户以及一组访问能力,用户基于其账户权限及访问能力访问提供商 的服务。可以采用以如下方式利用W3C的DID规范和W3C的可验证声明规范:
假设Alice需要一个身份(DID,唯一标识符)。如上图所示,为了创建一个 新的DID,Alice需要在区块链上创建一个数据项,该数据项中包含了随机 生成的标识符、指向其个人档案数据的链接、以及其个人档案数据的哈希。 档案数据中包含了公钥以及一组可验证的声明,所生成的随机标识符现在 成为Alice的DID,因为只有她持有与公钥对应的私钥。
可验证声明是由授权机构签名的通证,创建者同时也会在区块链上记录 声明数据的哈希,类似于DID的实现方式。
Alice首先前往权威机构获取可验证声明。例如,个人注册部可能是姓名、 地址、出生日期这些信息的负责机构。假设权威机构签发了可验证的声明, Alice首先展示其对DID的所有权,然后提交对可验证声明的请求。为了更新 其个人档案数据,Alice需要在区块链中添加一个新的数据项,其中包含 更新后的个人档案数据的新的哈希。
在验证Alice对DID的所有权时使用的挑战-应答协议,验证者会生成一个随机 种子,然后使用ALice的公钥进行加密,接下来Alice需要使用其私钥解密种子 以展示其确实持有公钥对应的私钥。
另一个希望识别Alice身份的用户或机构,例如Bob,首先会从Alice处接收到 DID,然后从区块链上读取所有该DID相关的数据并进行验证。Bob可以同样的 挑战-应答方式验证Alice的身份。
联盟链
联盟链,只针对特定某个群体的成员和有限的第三方,内部指定多个预选的节点为记账人,每个块的生成由所有的预选节点共同决定,其他接入节点可以参与交易,但不过问记账过程,其他第三方可以通过该区块链开放的API进行限定查询。为了获得更好的性能,联盟链对于共识或验证节点的配置和网络环境有一定要求。有了准入机制,可以使得交易性能更容易提高,避免由参次不齐的参与者产生的一些问题。
区块链的数据到底什么时候是存储在链上,什么时候又储存在相应节点的数据库中间呢?
我们必须了解清楚两个概念:
- 区块链数据;
- 链上数据;
首先:区块链数据(包括区块数据和状态数据两者)
- 区块数据描述的实际是区块链上面发生的每一笔交易的记录(如小帅给小王转账了50元,小帅充值了20元之类的数据)
- 而状态数据则是记录了每个账户和智能合约的当前状态(如小帅余额200元,小王20元)
而无论是区块数据还是状态数据都是由我们的区块链节点使用和储存的,区块链节点是一个程序,允许在我们的电脑,虚拟机等上,而多个节点通过网络的方式进行链接最终形成了完整的区块链网络。
而这其中区块链节点的数据存储最普遍的方式就是存入我们的磁盘中间,而我们的区块链不会直接的访问我们的磁盘,而是通过特定的数据库如LevelIDB,RocksDB,MySQL等独立和分布式的数据库来操作我们的数据(目前最重要的另外一个技术就是加入缓存区域,减少磁盘的寻道时间,加快区块链对磁盘数据的使用和存储),而相比于直接访问磁盘,用数据库作为中间媒介的特定数据访问模型对区块链节点更加的友好。
所以数据存储的过程可以解释为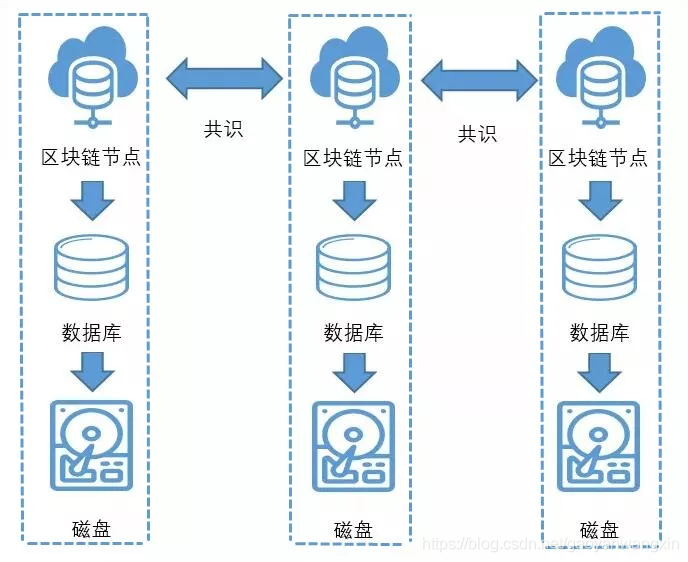
而数据库分为独立和嵌入式:其最大的区别就是是否需要独立的部署,嵌入式的数据库和区块链节点整合在同一个进程中间,同动同停,基本感受不到独立的存在感。
其次:链上数据
解释:链上数据是直接或者间接由区块链共识产生的数据;
- 而回到我们的问题,我们会发现区块链中间的区块数据和状态数据并不是凭空的产生的,区块中间的数据是因为不同节点之间的交易数据存储然后被广播到所有区块链节点的共识状态,所以区块数据也是因为共识而产生的数据之一;
- 而反观状态数据,由于交易的产生,共识的一致,最终会引起状态的改变,所以在此角度中间,状态数据也一样可以被认为是链上数据;