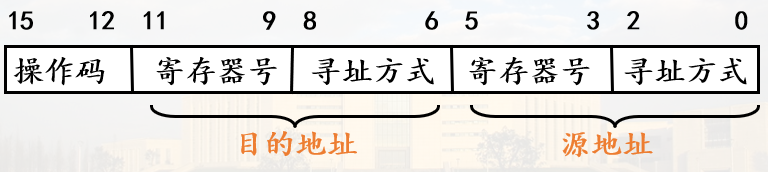
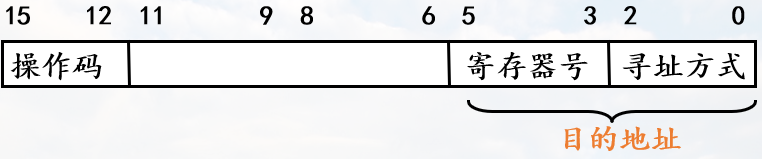
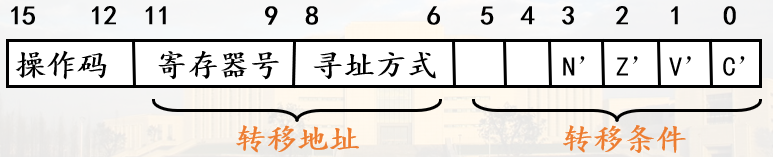
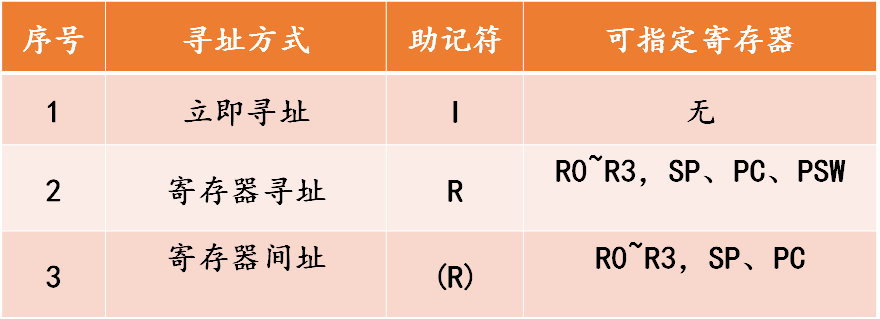
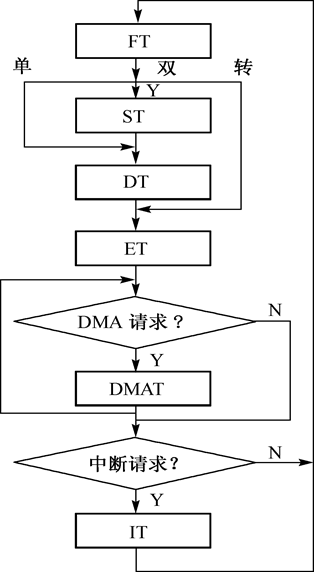
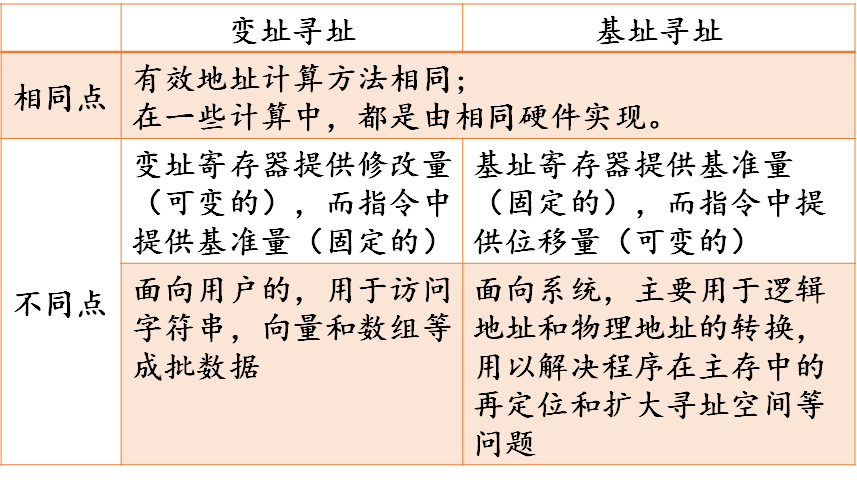
中断
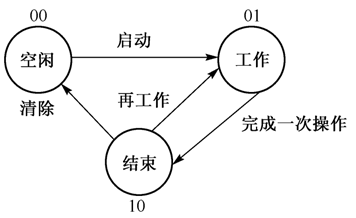
CPU有这样一种功能:在执行完当前指令后,检测到cpu外部发送过来的或内部产生的一种特殊信息,且可以立即对接收到信息进行处理,这种信息呢,就叫中断信息。
内中断
当CPU内部有什么事情发生的时候,将产生需要马上处理的中断信息呢?对于8086来说,当cpu内部有下面的情况发生时,产生相应中断;
- 除法错误,比如,执行div指令产生的除法溢出;
- 单步执行;
- 执行into指令;
- 执行int指令。
上面的四种中断源,在8086中中断类型码如下。 - 除法错误:0
- 单步执行:1
- 执行into指令:4
- 执行int指令,该指令的格式为int n,指令中的n为字节型立即数,是提供给CPU的中断类型码。
cpu收到中断信息后,需要对中断信息进行处理,需要对不同的中断信息编写不同的处理程序。
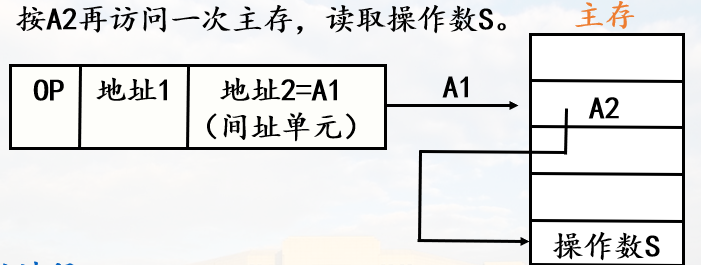
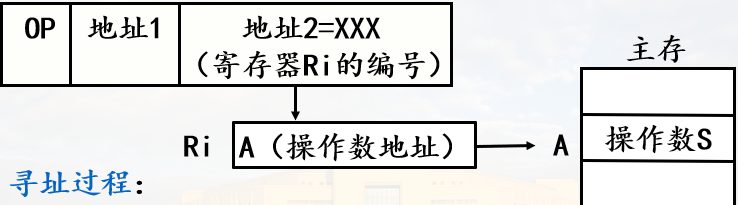
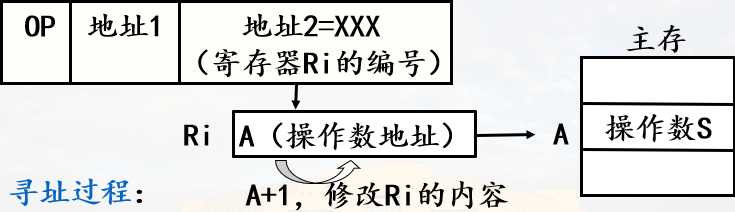
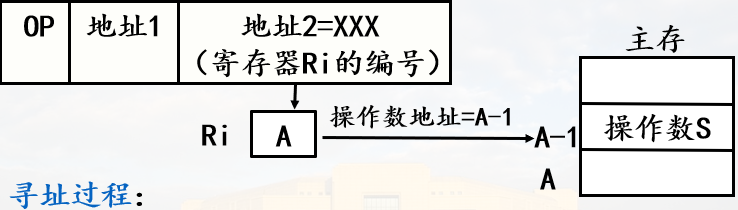
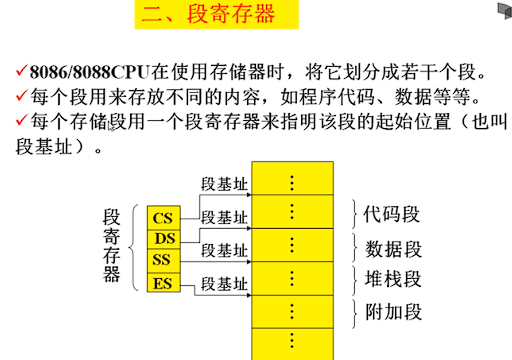
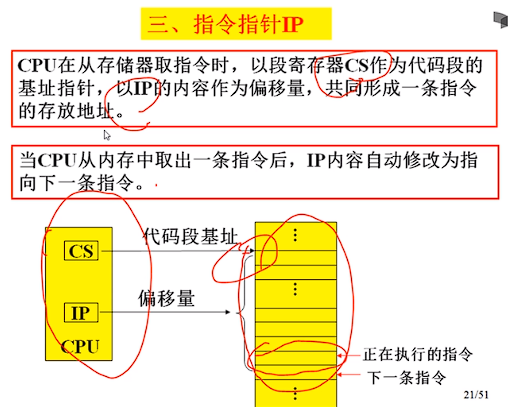
若要定位中断处理程序,需要知道它的段地址和偏移地址
中断向量表就是中断向量的列表,中断向量就是中断处理程序的入口。
中断过程:
中断类型码->中断向量表->修改CS:IP->中断处理程序
- (从中断信息中)取得中断信息码;
- 标志寄存器的值入栈(因为在中断过程中要改变标志寄存器的值,所以先将其保存在栈中);
- 设置标志寄存器的第8位TF和第9位IF的值为0(以后解释)
- CS的内容入栈;
- IP的内容入栈;
- 从内存地址位中断类型码*4 和中断类型码*4+2的两个字单元中读取中断处理程序入口地址设置IP和CS。
中断处理程序
中断信息可能随时被检测到,所以中断处理程序必须一直存储在内存某段空间之中。中断处理程序入口地址,即中断向量,必须存储在对应表项中。
- 保存用到的寄存器;
- 处理中断
- 恢复用到的寄存器
- 用iret指令返回。
iret:
pop ip
pop cs
popf
经典除法中断(0号中断)
再实现
1 | cs:code |
效果: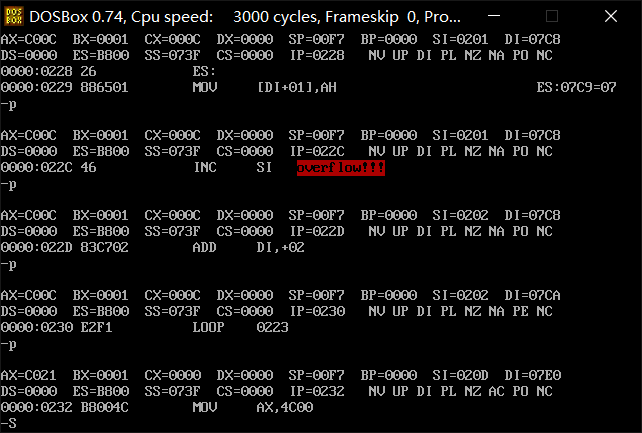
int
int n ;引发中断过程 过程:
- 取中断类型码n
- 标志寄存器入栈,TF=0,IF=0
- CS、IP入栈
- (IP)=(n*4),(CS)=(n*4+2)
- 执行中断处理程序aaaa是多少就是int多少
1
2mov word ptr es:[aaaa*4],200h;写入中断向量表入口地址ip
mov word ptr es:[aaaa*4+2],0;cs
BIOS/DOS提供的中断例程
在系统的ROM中存放着一套程序,称为BIOS,主要有:
- 硬件系统的检测和初始化程序;
- 外部中断和内部中断的中断例程;
- 用于对硬件设备进行I/O操作的中断例程;
- 其他和硬件系统相关的中断例程。
DOS中也提供了中断例程,DOS的中断例程就是操作系统向程序员提供的编程资源。
BIOS中断例程应用
int 10h的使用
1 | cs:code |
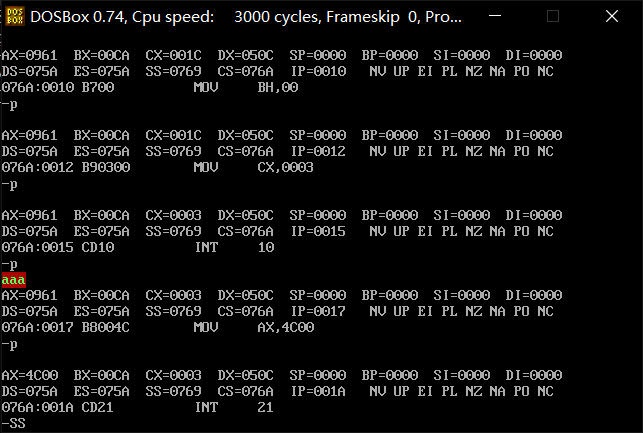
DOS中断例程应用
经典:
1 | mov ax,4c00h |
int 21h ; DOS提供的中断例程,包含了很多子程序
我们使用4ch号功能,即程序返回功能
1 | mov ah,4ch;程序返回功能号 |
又如:
在屏幕的5行12列显示字符串“Welcome to cloud”
端口
在访问端口的时候,cpu通过端口地址来定位端口。因为端口所在的芯片和cpu通过总线相连,所以,端口地址和内存地址一样,通过地址总线来传送。在pc系统中,cpu最多可以定位64KB个不同的端口。则端口地址的范围为0~65535。
对端口的读写不能用mov,push,pop等内存读写指令。只能用in和out这两条,分别用于从端口读取数据和向写入数据。
在in和out指令中,只能使用ax或al来存放从端口中读入的数据或要发送到端口中的数据。访问8位端口时用al,访问16位端口时用ax。
对0~255以内的端口读写:
in al,20h
out 20h,al
对256~65535端口读写,端口号放在dx中:
mov dx,3f8h
in al,dx
out dx,al
CMOS-RAM
PC机中,有一个CMOS RAM芯片,一般简称位CMOS。特征如下:
- 含一个实时钟和一个有128个存储单元的RAM存储器(早期为64个字节)。
- 该芯片靠电池供电。所以关机后其内部的实时钟仍可正常工作,RAM中的信息不丢失。
- 128个字节的RAM中内部实时钟占用0~0dh单元保存信息,其余大部分单元用于保存系统配置信息,供系统启动时BIOS程序读取。BIOS也提供了相关的程序,使我们可以再开机的时候配置CMOS RAM中的系统信息。
- 该芯片内部有两个端口,端口地址为70h和71h。CPU通过这两个端口来读写CMOS RAM。
- 70h为地址端口,存放要访问的CMOS RAM单元的地址;71h为数据端口,存放从选定的CMOS RAM单元中读取的数据,或要写入到其中的数据。可见,CPU对CMOS RAM的读写分两步进行,比如,读CMOS RAM的2号单元:
- 将2送入端口70h;
- 从端口71h读出2号单元的内容。
shl/shr
shr和shl是逻辑移位指令
shl逻辑左移
- 将一个寄存器或内部单元中的数据向左位移;
- 将最后移出的一位写入CF中;
- 最低位用0补充;
- 如果移动位数大于1时,必须将移动位数放在cl中。
shr是逻辑右移指令,与shl相反。 - 将一个寄存器或内存单元的数据向右移位。
- 将最后移出的一位写入CF。
- 最高位用0补充。
用法与shl一致。
实战

在屏幕中间显示当前月份
1 | cs:code |

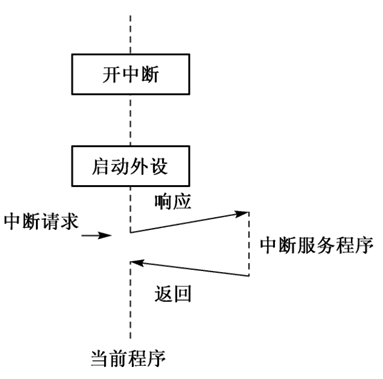
外中断
- 可屏蔽中断
sti:IF置为1,响应中断
cli:IF置为0,不响应可屏蔽中断 - 不可屏蔽中断
8086CPU,不可屏蔽中断的中断类型码固定为2
还是in,out